 书享界
书享界

版权声明
来源:财联社、书享界(readsharecn)
作者:黄仁勋
6月1日,英伟达创始人兼CEO黄仁勋在中国台北发表英伟达GTC台北2026主题演讲。
此次演讲中,黄仁勋重点发布了Vera Rubin架构、面向AI Agent的CPU Vera、AI模型Nemotron 3 Ultra以及AI工厂平台DSX等多项新产品与新平台。
同时,英伟达也进一步释放进军下一代AI PC市场的信号,目标是整个Windows阵营。
英伟达在发布会透露,包括比亚迪、吉利、极氪、小米以及小马智行等在内的中国主流车企和自动驾驶公司,均已采用或正在基于NVIDIA Hyperion 平台开发智驾。以下为演讲实录:
黄仁勋:欢迎来到GTCTaipei。非常高兴见到大家。回到家乡的感觉真好。我把父母也带回来了。我的父母在哪里?请大家为我的爸爸妈妈鼓掌,也请为暖场节目里的明星们鼓掌。女士们、先生们,看看他们有多可爱——台湾的明星。
今天来到现场的人非常多。我们还正在向台湾各地另外70个线下观看会场直播,70场活动同时进行,大家都在观看这场主题演讲。今天有很多内容要分享,也有许多合作伙伴需要感谢。
NVIDIA在台湾的生态系统已经发展得如此庞大,令人难以置信。人们提到“生态系统”,通常会想到NVIDIA的软件栈,以及建立在NVIDIA计算系统之上的开发者生态。但NVIDIA的生态系统向上游延伸至台湾的整条供应链——一切从这里开始;向下游则一直延伸至数据中心,最终抵达终端用户。
今天,我们几乎会谈到整个生态系统。这里有太多公司,也有许多我最喜欢的生态合作伙伴。台湾拥有极其丰富的生态系统,是全球最好的供应链生态系统。感谢大家来到这里。今年,我们共同推动的业务正在高速增长。昨晚有人告诉我,台湾今年的GDP增速接近10%,令人难以置信。
1
UsefulAI已经到来
从生成式AI到AgenticAI
令人难以置信。好了,今天有很多内容要谈,我们开始吧。
两年前我来到这里时,就开始谈到AI已经从生成式AI走向之后的浪潮。下一波浪潮就是AgenticAI。今天,我们可以说:AgenticAI已经到来,真正有用的AI已经到来。
这意味着什么?这里展示的是GitHub。当然,软件编程是AgenticAI最早落地的应用之一。软件开发是最有价值的职业之一,也是一个非常庞大的生态系统。全球大约有三四千万名职业软件开发者,此外可能还有数以亿计的学生、爱好者等。也就是说,世界上大约有三四千万人以编程为职业,这张图基本代表了他们。
这里展示的是GitHub上的代码提交与合并请求。Commit用于记录代码变更,PullRequest则用于请求将修改合并回项目。2023年的commit数量约为3亿次,2024年约为4亿次,2025年约为5亿次。到了2026年的前几个月,这个数字已经接近此前的三倍。
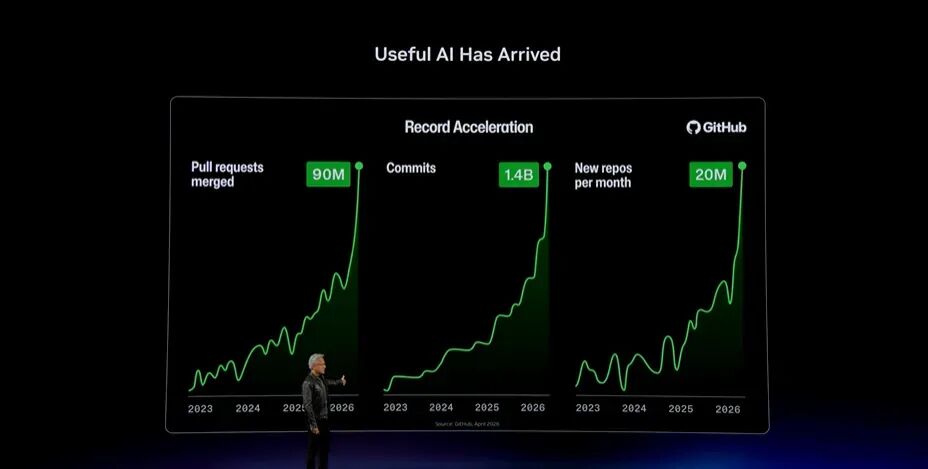
这意味着什么?三千万名软件开发者,对应大约3万亿美元的GDP——也可以理解为他们每年的薪酬规模。这3万亿美元又会为其他行业创造经济增长,影响全球大约100万亿美元规模的产业。现在,同样约3万亿美元的薪酬正在产生接近三倍的产出,相当于形成约9万亿美元的生产力。这个差异极其惊人。这就是AI的潜力,也是AI的承诺。
软件工程师的数量实际上还在增加。有人会讨论AI是否会减少就业,我认为这种说法完全不成立。
AI正在促使企业招聘更多软件工程师。原因很简单:如果聘用软件工程师能够创造相当于9万亿美元的生产性工作,企业为什么不招聘更多软件工程师?
如果那条产出曲线保持平坦,企业显然会减少招聘;但正因为产出如此惊人,企业会希望聘用更多软件工程师。这种影响很快会在经济中体现出来。因此,第一条判断是:有用的AI已经到来。
Token成为可盈利的收入单位
从产业角度看,这意味着Token的需求会急剧上升。因为只要这种生产力能够实现,大家就会希望获得更多。
Token已经成为能够带来利润的收入单位。既然它已经可以盈利,AI公司就会希望生成更多Token,建设更多AI工厂。
这正是台湾计算需求快速增长的原因,也是大家如此繁忙、业务表现如此强劲的原因。事实上,这甚至看起来有点像某些公司的股价走势。
计算模式已经改变,一切都改变了。第一条核心判断是:有用的AI已经到来。AI正在成为利润生成器,也正在成为GDP生成器。其背后是一种全新的计算模式:不再只是一个大语言模型,而是一个Agent。
2
AgenticAI:新的计算模式
今天几乎所有内容都会建立在这个基础上。我先用一点时间解释内部发生了什么。这是一个Agent,也就是一个Agent应用。
过去,这里会是应用程序、代码和操作系统:应用代码运行在应用程序中,再运行在操作系统中。
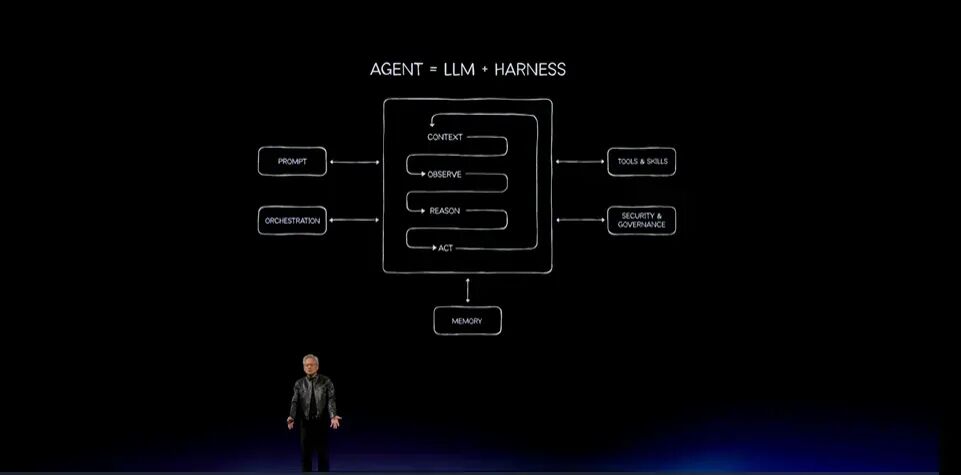
今天,它变成了Agent:一个或多个大语言模型位于Harness(编排框架)中,由Harness帮助模型协调执行真正有生产价值的工作。
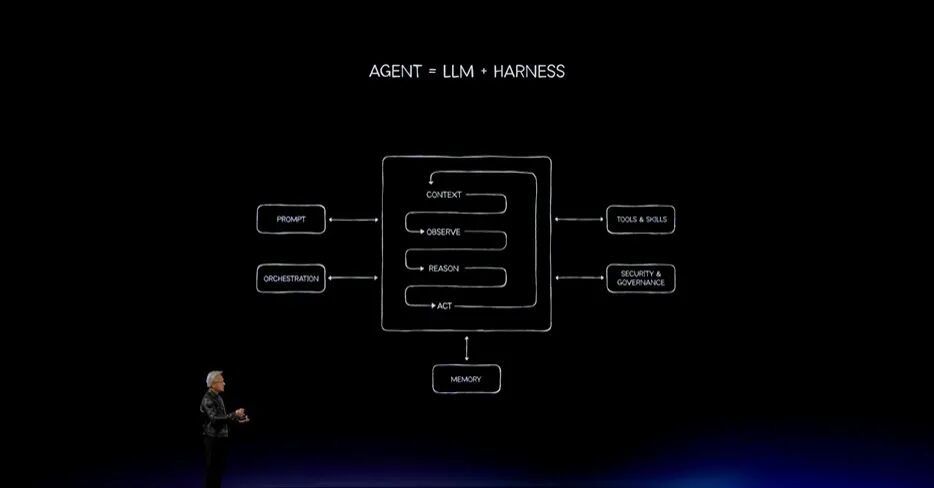
输入到来之后,Agent必须理解、观察、推理、行动,并使用工具。工具可以是电子表格、网页浏览器、数据处理引擎或数据库引擎。
整个过程需要编排。Harness负责信息路由。无论是处理上下文、理解正在发生什么、推理下一步要做什么、制定可执行计划,还是依据计划采取行动,这条路径上的每一步都由软件编排。
因此,这从根本上说就是一个Agent。它需要处理短期记忆,也就是工作记忆;还需要处理长期记忆,就像人类也拥有长期记忆一样。因此,内存管理系统极其重要。整个系统才叫Agent。大语言模型负责思考,Harness像操作系统一样把所有部分连接起来。这就是新的计算模型。
Agent使用工具完成任务
Agent能够完成非常惊人的事情。真正的突破在于两类技术同时汇聚:一方面,大语言模型已经能够更好地思考、推理、规划和使用工具;另一方面,我们已经拥有能够管理记忆、执行编排并调用工具的Harness。两者结合后,AI可以完成过去难以想象的工作。
我举几个例子。这是Prompt,这是生成的代码,这是最终得到的结果:一边是输入,一边是输出。大家觉得怎么样?非常惊人,对吧?这里使用的是ClaudeCode,但Codex同样可以完成非常出色的工作。
另一个例子是:生成一个GIF。Prompt大意是,让NVIDIA绿色光点在黑色背景上散开,再聚合成台北101、GTC Taipei 2026和NVIDIA标志,随后再次散开并循环播放。
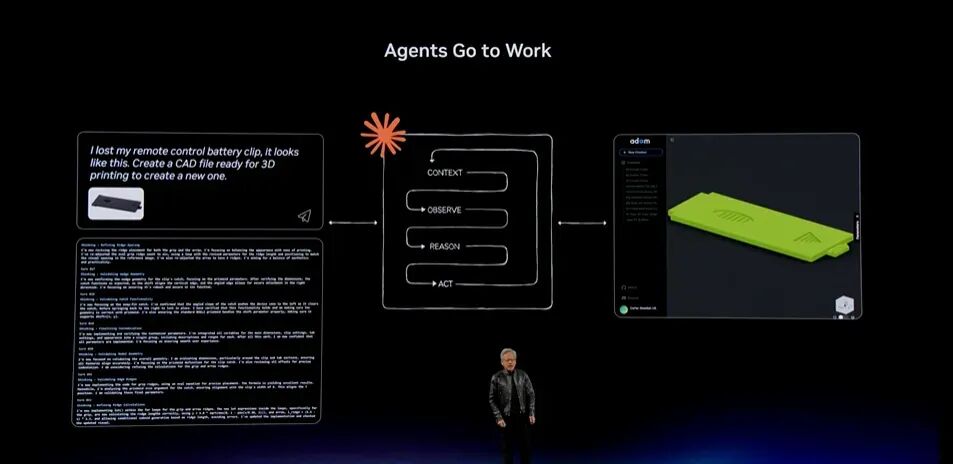
再看下一个例子:我的遥控器电池仓卡扣丢了,它原本长这样。请生成一个能够直接用于3D打印的CAD文件,做一个新的卡扣。Agent会调用工具完成任务。
明白了吗?这就是新的计算模式。过去,我们打开应用程序、点击、输入;现在,我们只要向AI说明自己的意图,AI就会生成代码或调用工具,产生需要的结果。未来,计算机就是这样工作的。
软件公司的机会:把软件变成Agent可调用的工具
这就是AgenticAI。过去两年,我们一直在为它做准备,现在它已经到来。其中一个关键突破当然是工具调用。
很多人曾经对我说:“Jensen,AI就要来了,AgenticAI就要来了,所以软件公司都会失去生意。”我的回答恰恰相反。因为未来会有数量巨大的Agent,世界不再受限于人类用户的数量。因此,Agent会使用比以往更多的软件工具。
对软件公司而言,这是一个极好的时代。但软件必须以Agent可以使用的方式呈现。这是一个重大突破。大家都知道,NVIDIA最宝贵的资产之一就是CUDA库,我把它们称为CUDA-X库。这是NVIDIA的珍宝。
今天,我们可以把这些CUDA-X库提供给Agent,而Agent使用它们的效率甚至可能超过人类。因此,CUDA-X将迎来极其重要的价值释放。让我们来看一下。
CUDA-X库成为Agent的技能
二十年前,我们创建了CUDA:一个用于加速计算的统一架构。我们重新发明了计算。今天,大约1000个CUDA-X库帮助开发者在科学和工程的各个领域取得突破。
CUDA-X库也会成为Agent的工具。例如:用于计算光刻的cuLitho、用于决策优化的cuOpt、用于直接稀疏求解的cuDSS、用于结构化与非结构化文档深度研究的AI-Q、面向AI-RAN的Aerial、用于可微分物理的Warp,以及用于基因组学的Parabricks。其基础都是算法,而算法非常美。请大家为数学之美鼓掌。
软件的计算模式将会发生改变。回到这张图:这就是Agent。它是终极的解耦式、分布式计算模型。为了处理一个Agent,许多不同计算机会被激活。Agent由模型、Harness、工具与技能,以及Runtime组成,它们会运行在数据中心的不同位置。
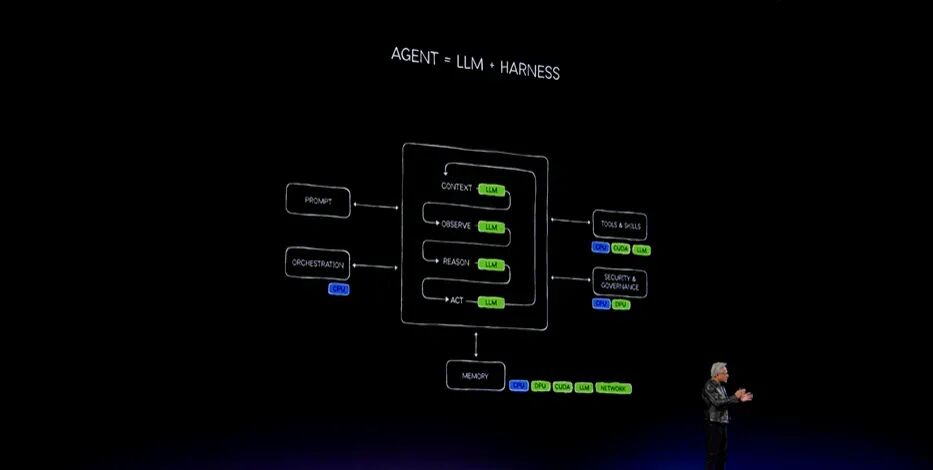
可以把模型视为大脑,把Harness视为身体,把Runtime视为车间,把工具视为工人在车间里使用的器具。当然,这一切会以极大的规模运行,每一个步骤都可能在计算机的不同部分执行。
当大语言模型进行思考、处理上下文、观察并理解环境、推理、制定计划并执行计划时,整套Grace Blackwell NVL72机架都可能被激活。当Agent调用工具时,CPU也会参与。这个工具可以是C编译器,也可以是Python、JavaScript或加速计算。
内存、CPU、DPU与安全
今天的Agent还只是相对简单的工具使用者,未来会成为非常复杂的工具使用者。这正是CUDA-X库会在Agent时代变得非常受欢迎的原因:它们能够解决世界上许多最重要的问题。
所有CUDA-X库都会附带Agent可以学习的技能。可以把技能理解为一本使用说明书:AI读完以后就会明白,原来这个库应该这样使用。Agent使用这些库的能力会极其强大。因此,工具会运行在CPU、GPU和大语言模型之上。
安全Harness运行在CPU和一种名为DPU的安全处理器上,也就是NVIDIA BlueField。所有流程的编排也运行在CPU上。这里展示的就是整个Harness,而CPU负责协调全部工作。
其中最困难的部分之一是内存。工作记忆也就是KVCache。系统需要决定记住什么,如何执行Compaction——这不只是压缩,还包括如何检索。应该检索结构化数据,还是非结构化数据?不同数据之间的本体关系是什么?
整个过程极其复杂。AI的内存系统会推动存储系统彻底革新。大家可以看到,这种计算模型、这种计算模式,以及名为Agent的新应用,与过去完全不同。过去,一大批软件被装进二进制文件,再运行在操作系统中。如今,这是一个解耦式、分布式、异构计算问题。
这正是我们构建下一代Vera Rubin的原因。Vera Rubin不是一颗芯片,也不只是GPU。它从GPU开始,但端到端的整套系统都属于Vera Rubin:RubinGPU、NVLink、用于协调系统的VeraCPU,以及之后会进一步介绍的其他组件。
存储系统同样具有革命性。Vera、ConnectX-9、软件栈DOCA,以及系统内部的安全处理器协同工作,让所有内容在静态、传输和使用过程中都处于加密状态。由于AI模型极为宝贵,整套系统必须满足机密计算要求。其中每一个组成部分单独拿出来都足以构成一次变革。
Vera Rubin是NVIDIA历史上最雄心勃勃的工程。公司全部约四万名工程师都参与其中,在座各位也参与了整套系统的创造。Vera Rubin是一个奇迹,而且它远远不只是一颗芯片。

3
从GPU公司到AI基础设施公司
客户真正需要的是AI工厂
很久以前,NVIDIA是一家GPU公司。随着时间推移,我们不断演化,成为一家系统公司。现在,大家看到的是从头设计的、极其复杂的系统。
但归根结底,我们的客户和合作伙伴并不只是想购买计算机,他们想建设AI工厂。因此,NVIDIA正在再次转型。越来越多技术已经扩展到整个基础设施尺度,合作伙伴也延伸至基础设施层:发电设备、制冷系统和电网供应商。许多工业企业都成为生态系统的一部分。
我们的目标是构建完整技术栈,就像过去构建GPU、构建Grace Blackwell NVL72一样。如今,我们正在构建全栈系统,让客户能够建设卓越的AI基础设施。让我们来看一下。
DSX:AI工厂的参考设计与运营框架
世界正在竞相建设AI工厂,这是人类历史上规模最大的基础设施建设浪潮。AI工厂极其复杂:芯片、机架、网络、电力、制冷和电网,每一层都必须端到端协同设计,因为算力就是收入。
NVIDIA DSX是建设和运营AI工厂的蓝图,也是一套参考设计,目标是实现最高效率和盈利能力。
在一台机架落地之前,合作伙伴就可以使用DSX Sim进行高保真仿真,并借助Omniverse DSX Blueprint生态设计和验证Vera Rubin AI工厂:规划布局、模拟电力和制冷、设计网络、验证每一次集成,并在数字孪生中测试每一项变更。工厂通电后,DSXOS会接管基础设施的配置、运营、监控和修复,把已经安装的系统转化为可信、多租户、具备韧性的AI就绪算力。
当前AI工厂往往需要预留最多约40%的电力冗余。DSX Max LPS可以让运营商在同一电力预算中安全部署更多GPU,从而增加数十亿美元的年度收入。45°C液冷方案可以降低水耗和能耗,把更多电力留给产生收入的计算。动态功率分配会在机架之间调度电力,回收闲置瓦特,并把功率送往真正执行任务的位置。功率平滑可以压低整个工厂的峰值电流和电力浪涌。AI Agent团队会与DSX Max LPS持续协同,在制冷、电力和工作负载需求之间保持平衡。
DSX AI工厂还可以成为灵活的能源资产,与电网友好协同。DSX Flex读取实时电网信号,在电网需要缓解压力时动态调整工厂功率。到本十年结束前,预计会有100GW的AI工厂上线。NVIDIA DSXAI工厂将以最高效率运行,生产成本最低的Token,同时让电网更加强韧。

AI工厂生态与每瓦收入
过去,我展示过计算生态系统:NVIDIA的计算层、软件和计算栈被集成进第三方平台与库,服务最终市场。那是计算生态系统。今天展示的则是AI工厂生态系统。
对于在座各位而言,这属于更下游的位置:我的上游是大家,我们的下游则是这套生态。因为NVIDIA最终不再只是制造GPU,也不只是制造系统,而是在帮助客户建设极其复杂的AI工厂和AI基础设施。
一座1GW级AI工厂的投入,最初可能是200亿至300亿美元,后来达到500亿至600亿美元,未来甚至可能达到每GW800亿至1000亿美元。把1000亿美元投入一座AI工厂,它必须一次成功,并且立即开始运行。资本成本和系统复杂度都极高。
过去,我们在计算机中设计芯片,再用计算机模拟系统。今天,大家刚刚看到,一切都可以在Omniverse中构建。我与大家一起推动Omniverse已经很长时间,这正是梦想实现的时刻:在真正破土动工、投入资本之前,我们就能先在数字框架、数字模拟器和数字世界中建设与验证这些巨型系统。
这套生态系统叫作DSX。RTX面向GPU,DGX面向系统,而DSX面向基础设施。正因为我们覆盖包括系统与软件在内的完整技术栈,NVIDIA才能够帮助小型公司成长为世界级AI云厂商。CoreWeave曾经也是小公司,如今估值已经达到数百亿美元并快速增长;我们最近也与Nebius合作,它同样增长迅速。
这些云厂商拥有非常出色的客户,例如软件编程公司Cursor、图像生成公司Black ForestLabs、世界基础模型公司WorldLabs、金融科技公司Revolut和Shopify。
另一个例子是Nscale,其客户包括英国电信。Google也在使用我们的AI云。还有前沿实验室Thinking Machines、韩国的NAVERCloud,以及包括韩国央行、现代汽车在内的客户。
印度有Yotta,新加坡企业正在澳大利亚建设基础设施,印度尼西亚也有合作伙伴。每一家公司都在服务区域与全球客户。AI会在所有地方运行,每一家公司都会由AI驱动,每一个地区都会建设自己的AI能力。印度尼西亚有Indosat,台湾有GMI——可以鼓掌。
机会非常大,但这些企业都需要若干关键要素。首先当然是底层计算栈:硬件、软件、库,以及NVIDIA与全球第三方开发者生态的连接。这些能力让任何企业都有可能搭建AI云。
不过,今天的AI云已经高度复杂。刚才展示的是软件和计算机科学视角;从资金和资产视角看,它是一座巨型工厂。仅仅拥有计算技术还不够。这正是NVIDIA成为AI基础设施公司的原因。帮助客户建设和部署AI工厂,已经变得极其重要。
原因很简单:算力就是收入,算力也就是利润。缺少收入和利润,就意味着损失。AI基础设施上线时,可能很快,也可能很慢;吞吐量可能高,也可能低;韧性与可靠性可能好,也可能差;可用寿命也可能长短不一。而它对应的是从500亿、600亿美元逐步走向1000亿美元的资产投入。
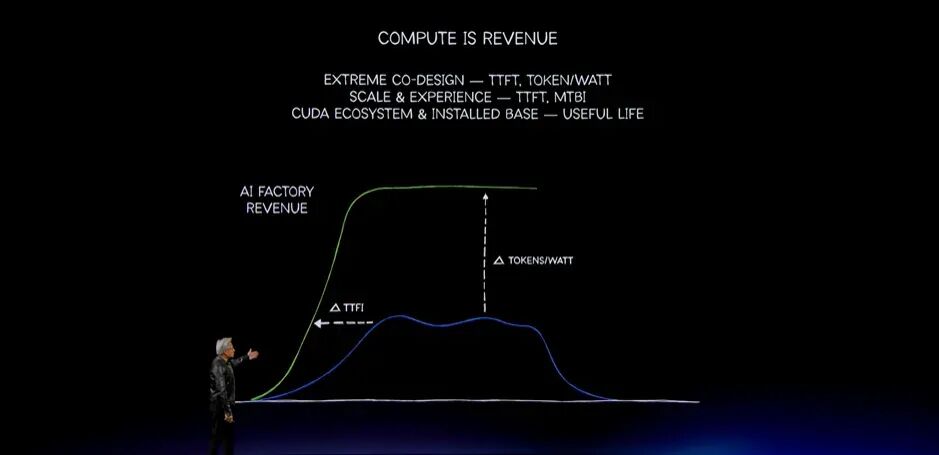
这条曲线极其重要。NVIDIA之所以能够成为优秀合作伙伴,是因为具备完整集成能力。我们不是只做了一份PowerPoint,而是真正构建了整套基础设施,把所有部分连接起来,并且亲自建设了价值数十亿美元的系统,确保一切运行良好。因此,我们实现首个Token、首次推理和启动训练的时间都更短。
第二个关键是每瓦吞吐量,也就是每瓦能够生成多少Token。NVIDIA的表现处于世界级水平,因为我们从头集成并设计所有组件,模拟整套系统,并采用Extreme Co-Design。刚才展示的Vera Rubin机架就是例子:每一项设计都服务于极高吞吐量。
如果数据中心或AI工厂只有1GW电力,它不会凭空获得更多电力。1GW就是1GW。在电力约束下,每瓦吞吐量就是收入,因为每一个Token都能够产生收入。这就是未来:算力就是收入,性能就是收入。仅仅因为芯片便宜就选择错误架构,并没有意义。真正应该关心的是每瓦收入:购买越多,赚得越多。
第三个关键是可靠性。如果亲自看过这些数据中心,就会发现其中有太多运动部件和数以百万计的线缆。让所有计算机长期协调、可靠运行,极其困难。NVIDIA已经长期运营超大规模系统,这种经验非常重要。平均中断间隔等指标极其关键。
最后一个关键是系统寿命。这很困难,因为软件一直在变化。四年前的Hopper时代已经与今天完全不同,六年前的Ampere时代同样完全不同。最初我们讨论CNN,之后讨论Transformer,再之后讨论MoE,如今则讨论Agentic系统。软件行业每隔几个月就会提出新技术。如果架构缺乏灵活性、生态不够丰富,系统的有效寿命就不可能足够长。
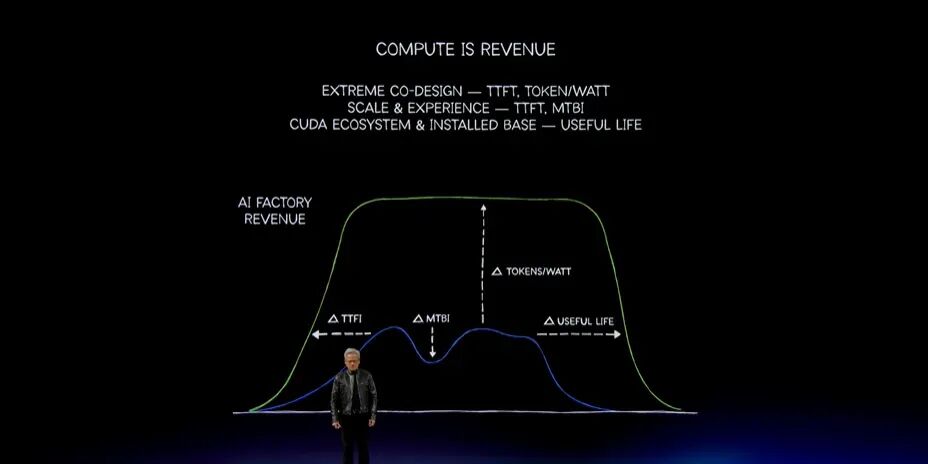
NVIDIA系统遍布世界,软件开发者从CUDA开始,因此生态系统和资产的有效寿命会更长。归根结底,这会影响成本。也可以从收入角度理解,但收入的另一面就是成本。资产寿命越长,总拥有成本越低。这就是差异:在算力经济中,购买越多,赚得越多。
台湾供应链正在与NVIDIA一起亲历这一切。各地工厂如此繁忙,员工如此努力,是因为大家意识到有用的AI和可盈利的AI已经到来,计算需求极高,而算力正是约束条件。我们需要努力帮助世界各地建设AI工厂。
我非常高兴能够站在这里告诉大家:Vera Rubin已经进入全面量产爬坡。为Vera Rubin构建的供应链规模是Grace Blackwell的两倍。过去组装一台Grace Blackwell机架需要两小时,现在只需要五分钟。产能更高,生产节拍也更快,而我们需要这一切来支持需求。数百万平方英尺的厂房已经上线,用于支持Grace Blackwell,并正在为Vera Rubin爬坡做准备。我要感谢大家。Vera Rubin已经进入全面量产爬坡阶段。

4
Vera Rubin:为AgenticAI打造的五机架平台
Vera Rubin量产影片:从芯片到五机架系统
(此处为视频)
大语言模型能够生成答案。现在,AIAgent已经能够完成工作,但处理AgenticAI是一种完全不同的问题。Agent需要观察、推理、规划和使用工具;需要管理庞大的上下文,在工作记忆与长期记忆之间切换;还需要按需启动具有不同专长的子Agent。
NVIDIA Vera Rubin是一套多机架、Pod级系统,专门用于处理AgenticAI,目前已经进入全面量产。供应链中的制造自动化与流程编排令人惊叹。我们的旅程始于第一台AI超级计算机NVIDIADGX-1。此后的十年中,我们不断把每一颗芯片和每一套系统推向极限:从Pascal和第一代NVLink,到第一套机架级AI超级计算机Grace Blackwell,再到今天第一套为Agentic时代打造的多机架、Pod级超级计算机Vera Rubin。
一切从台积电开始。组成Vera Rubin的七颗新芯片,要经过数百道工艺步骤,采用3纳米制程。随后是CoWoS-R等先进封装流程,以及来自Micron、SKhynix和Samsung的HBM内存。
Vera Rubin Compute Board集成约6万亿个晶体管,单块计算板上包含超过1.8万个组件。Vera Rubin NVL72负责“思考”:处理Prompt和上下文理解、推理与规划。
接下来是新的模块化Compute Tray。新的PCBMidplane设计让Superchip、ConnectX-9 Super NIC和BlueField-4 DPU全部在位连接,不再需要线缆,从而提高AI工厂规模下的韧性。整套系统包含18个Compute Tray、9个可热插拔NVLink Switch Tray、新型高效率歧管,以及承载超过5000安培电流的液冷Busbar——相当于20辆电动车同时全速加速。总计约130万个组件,共同组成第三代MGX机架设计。
祝贺Microsoft已经搭建并运行Vera Rubin NVL72工程机架,也祝贺Dell和CoreWeave完成Vera Rubin NVL72工程机架部署。
随后是Vera CPU Rack:一台液冷机架中集成256颗CPU,负责协调模型、搬运内存数据和启动工具调用。这些系统由Foxconn和Quanta制造。
Groq3LPX也在成形。它在32个液冷1UCompute Tray中集成256颗Groq3LPU,每个Tray包含8颗LPU。整套机架拥有40PB/s的片上SRAM带宽,面向超低延迟推理。
VeraBlueField-4STX是AI保存记忆的位置:由BlueField-4加速存储处理,并连接内存、存储与芯片级安全能力。
NVIDIA Spectrum-6SPX Ethernet Rack负责提供机架之间的高速以太网互连。平台还引入Spectrum-X Ethernet Photonics:一种采用CPO共封装光学技术的新型交换方案,用于支撑百万GPU规模的AI工厂。
五套相互连接的机架级系统共同组成Vera Rubin:一台面向AIAgent的超级计算机。台湾有150家供应链合作伙伴参与其中,数百万平方英尺的工厂空间、数百个站点,以及芯片、封装、系统和数据中心,都被推向尺寸、功率和规模的极限。这就是ExtremeCo-Design。我们与台湾共同完成了这件事,一起为AI时代重新发明计算。台湾从一开始就与NVIDIA并肩同行,而今天,我们正把Vera Rubin带向全世界。谢谢台湾。
现场展示:Vera Rubin不只是运行AI,而是运行Agent
女士们、先生们,Vera Rubin不只是为了运行AI而打造。Vera Rubin是为了运行Agent而打造。这是一套Agentic系统。
想象一下其中的复杂程度。Agent是计算机科学长期演进后出现的重要突破,它花了多年时间才真正释放潜力并开始创造价值。理所当然,运行Agent的计算机也必须是世界上最先进的系统。这就是Vera Rubin。让我们把Vera Rubin推出来。
【现场推入机架】这就是Vera Rubin NV L72;这是Groq 3 LPX。
下一届GTC,我会更详细地介绍这些系统,今天还有很多内容要讲。这是VeraCPURack:256颗CPU,全部采用液冷。
稍后我会继续介绍Vera。这是Vera BlueField-4STX存储处理和安全系统。当然,这里还有Mellanox网络系统,以及采用共封装光学技术的网络系统。所有这些卓越技术共同构成Vera Rubin。

当我们设计Hopper时,预训练是最重要的应用,也是当时最重要的工作负载。后来我们设计Grace Blackwell,很多人曾经说:“Jensen,NVIDIA擅长预训练,但推理太容易了,我们也能做。”大家还记得吗?
但大家都知道,推理就是收入。MoE模型非常复杂,而如果既要实现很短的响应时间、很快的交互,又要实现很高的吞吐量,难度极高。这正是我们创造NVL72的原因。
今天,NVIDIA的Token成本在全球处于最低水平,差距不是10%,而是倍数级、数量级的差异。这来自ExtremeCo-Design,也来自我们对推理计算模型和计算模式的理解。正因为如此,我们才能创造NVL72。
到了Vera Rubin,问题已经超越普通推理:它是在Agentic系统中执行推理。Vera Rubin Compute Tray没有线缆、没有软管、没有风扇。
上一次给大家展示系统时,机架里到处都是线缆,虽然视觉上很震撼,但现在中间有一块PCB连接两侧。过去组装需要两个小时,现在只需要五分钟。Vera Rubin的可靠性与韧性会达到非常高的水平。
这是VeraCPUTray,里面是有史以来最先进的CPU。稍后会详细介绍。这是存储Tray,包含两颗VeraCPU、BlueField-4、ConnectX-9和大量软件能力。这是面向极低延迟推理的新型Groq 3 LPX机架系统。吞吐量由Vera Rubin NVL72提供;如果还希望进一步降低延迟,可以增加GroqLPU。
这里是Vera Rubin NVLink Switch Tray,中间是NVLinkSwitch。这是一项革命性设计。旁边则是面向Scale-out的以太网交换机。
我们在Grace Blackwell时代推出了这两类网络系统。今天,NVIDIA已经成为全球规模最大的网络公司之一。我为网络团队感到自豪,网络是NVIDIA所有工作的重要使能层。接下来,我要介绍我们将进入的下一个重要产业。
5
VeraCPU:为Agent打造的CPU
从“为人类设计”到“为Agent设计”
接下来,我们谈谈CPU。VeraCPU是为AI时代打造的CPU。
此前的CPU都是为人类设计的。我们是CPU的用户和租用者。人类生活在以秒计算的世界里。云计算的CPU经济模型也是如此:核心越多,可以出租的资源越多。传统CPU的使用场景与经济模型,与Agent的需求有根本差异。
Agent没有耐心。它们生活在以纳秒计算的世界里。Agent调用工具时,希望尽快得到响应;访问数据库时,也希望结果立刻返回。Agent等待的每一刻,都会阻碍它进入下一步。因此,CPU的延迟必须尽可能低,交互必须尽可能快。我们为AI时代创造了VeraCPU。

在整套系统中,VeraCPU有三类用途。首先,Vera RubinNVL72用它来执行“思考”相关的协调工作。Vera RubinNVL72机架中已经集成VeraCPU。一套NVL72包含72颗RubinGPU和36颗VeraCPU,并通过NVLink6连接。VeraCPU负责协调和管理GPU、处理KVCache,并运行机架内部的软件与编排任务。
大家都知道,Vera Rubin平台也正在进入全面量产爬坡阶段,我们也已经销售数以百万计的Grace Blackwell。NVIDIA已经成为全球规模最大的CPU制造商之一。
系统还使用BlueField处理安全与隔离。
Vera Compute系统则用于运行Harness,协调AI模型、调用工具、访问数据库。旁边是数据服务器,也就是Vera BlueField-4STX:这是极快的存储服务器和存储系统。之所以如此重要,是因为Agent会以极高频率访问记忆。
这些存储服务器与CPU,已经成为数据中心最昂贵部分的关键路径。最昂贵的部分当然有其原因:AI工厂的经济模型围绕Token展开,而Token在GPU系统中产生。因此,我们当然希望尽可能多地制造和生成Token,也会把最重要的资本投入其中。CPU与存储系统不能成为阻碍。
这给CPU架构带来巨大压力。因此,我们从零开始设计了一套全新架构,一种前所未见的CPU,名字叫Vera。这是一颗为Agent打造的CPU。过去的CPU为人类打造,而这颗CPU为Agent打造。
请记住四个关键点。
第一,Vera的每时钟周期指令数(IPC)必须极高,因为我们需要缩短延迟和处理时间。重点不是吞吐量,而是单线程性能。Vera必须拥有世界级、甚至领先的单线程性能。因此,Vera的IPC极高:每个时钟周期可以取指、解码和执行十条指令。
第二,每个CPU核心搬运数据的带宽必须达到世界级水平,也就是每核带宽。
第三,是总体带宽。前面提到,Agentic系统从根本上是解耦式和分布式的。当计算解耦并分布运行时,网络就会成为问题。因此,我们必须尽可能快地在CPU核心之间、CPU与存储之间、CPU与GPU之间搬运数据。系统周边和CPU核心内部的带宽都必须达到世界级水平。
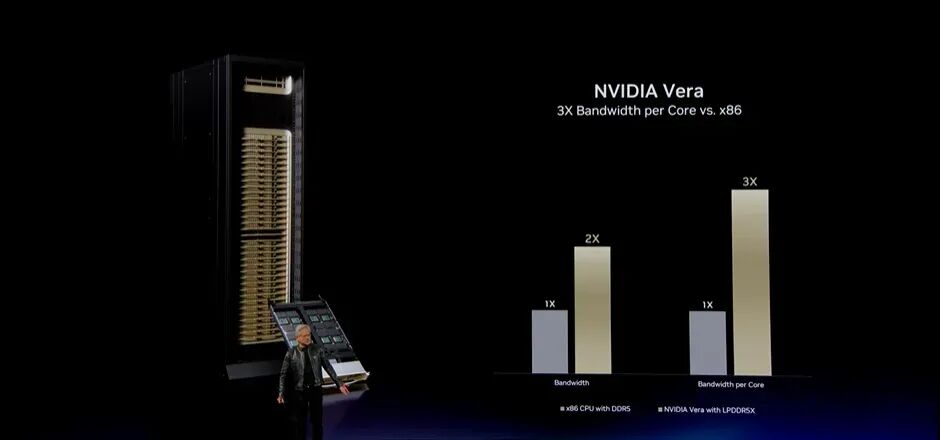
Vera是近年来少见的、真正达到Reticle Limit的CPU。它采用连接全部CPU核心的高速Fabric,带宽达到3.6TB/s。没有Chiplet,也没有跨越芯片边界,因为所有CPU核心都需要以极高带宽彼此通信。它们不是被一个个拆开出租,而是共同协作。
Vera的Cross-sectional Bandwidth极高。它率先支持PCIeGen6,也采用LPDDR5X,内存带宽达到1.2TB/s,是高性能CPU的两到三倍。芯片外部带宽大约是传统方案的三倍;芯片内部带宽、每核带宽和总带宽同样达到世界级水平。
前面已经展示过,系统中的CPU核心数和CPU数量会非常高。原因很简单:过去,我们为人类创造CPU,而人类用户的数量有限;未来会有数十亿Agent。Agent几乎没有耐心,因为旁边的GPU成本极高、价值极高。因此,CPU既要有高性能,也必须高度节能,让AI工厂能够部署尽可能多的CPU,又不至于从Token生成环节夺走太多电力。
因此,Vera由四项属性定义:每时钟周期指令数和单线程性能、每核带宽、芯片内部与周边的总带宽,以及能源效率。与性能最强的x86CPU相比,Vera的实际单线程性能提升极其显著。CPU性能提升5%已经很困难,提升10%也非常困难,而这种倍数级性能跃升过去几乎难以想象。这就是NVIDIA Vera。大家觉得怎么样?
VeraCPU影片:Olympus Core、SCF与LPDDR5X
(此处为视频)AgenticAI改变了CPU的角色。CPU现在是指挥家,GPU则是乐团。
传统CPU为另一个时代而设计:尽可能增加每个Socket中的核心数量,把它们切分、虚拟化,再按小时出租。在Agent时代,CPU会成为影响GPU利用率的瓶颈,直接影响Token吞吐量、响应延迟和用户体验。
NVIDIA Vera是为Agentic Loop打造的CPU。它将NVIDIA自研数据中心CPU核心与可扩展一致性互连Fabric结合,在性能、核心数和带宽之间取得合适平衡,从而最大化AI工厂产出。
Vera的核心是NVIDIA Olympus Core,面向现代数据中心工作负载设计,包括分支密集型Python Runtime、工具调用和沙箱代码执行。每个核心都针对性能进行了调优:神经网络分支预测器每个周期评估两条Taken Branch;10-wide Decode Engine每周期引入更多工作;大型乱序执行引擎保持指令持续流动;高级预取器与新的Graph Engine提前预测下一条数据路径。
但只有快速核心还不够,数据必须正确并及时抵达。Vera率先使用LPDDR5X内存,同时能够并行纠正多类错误,而不会牺牲带宽。与x86相比,Vera的内存峰值延迟降低约40%,让核心在检索、分析和沙箱执行过程中持续获得数据。
NVIDIA第二代Scalable Coherency Fabric将88个OlympusCore统一连接在单片Mesh上,内存和I/O使用独立Die。CPU核心不会被拆散到多个Chiplet中,因此核间通信速度比传统CPU快约50%。支持内存一致性的NVLink-C2C还会把GPU直接连接到Fabric。除GPU之外,NVLink-C2C还可以让Vera扩展至多Socket系统,为CPU之间提供极高带宽。
Vera在Agentic Sandbox工作负载上的性能达到x86CPU的1.8倍。独立的Vera Rack可以运行Agent沙箱、工具、代码和数据流水线,并与Rubin GPU紧密协同。Vera让加速工作流持续运行。NVIDIA Vera Blue Field-4STX则为上下文记忆和AI存储提供动力,集成计算、网络与存储。Vera是为Agent时代打造的CPU。
VeraCPU将成为新的增长引擎
Vera将成为NVIDIA新的重要增长引擎。目前已经出现了非常积极的评价。
请记住,Grace和Vera也是AI世界中获得最广泛适配的CPU。每一家数据中心、每一家云厂商、每一家企业,以及所有与NVIDIA合作部署AI的公司,都已经适配Grace。整个软件栈已经针对Grace优化。接下来,每家公司都会适配Vera。由于Vera会与Vera Rubin一起进入市场,Vera将成为优化程度最高的Agentic CPU。
在Grace Blackwell转型过程中,最大的风险来自外部x86CPU向GraceCPU的切换。这个转变风险很高,但我们的执行非常出色。如今,Grace已经与Grace Blackwell紧密绑定。人们提到Blackwell,常常会直接说Grace Blackwell,因为Grace已经无处不在。各家公司的软件栈和安全栈都已经针对它优化。
现在,Vera即将到来。我对此非常兴奋。
再看一些性能数字。实现加速并不容易,尤其是SQL。SQL是有史以来最著名的领域特定语言之一。在CUDA、OpenGL之前,就已经有IBM发明的SQL。今天,全球结构化数据库都在使用SQL。Vera运行SQL的速度达到传统系统的三倍。不是快10%,也不是快25%,而是达到三倍,非常惊人。
另一个例子是实时流处理。AI不会只阅读文档,它还会持续观察遥测数据,尤其是在工厂和证券交易所中。不断涌入的突发数据会进入CPU。VeraCPU在实时流处理任务上的性能达到传统方案的六倍。纽约证券交易所总裁Lynn Martin非常慷慨地与我们合作。这类系统会在全球实时运行。
Vera CPU之所以能够实现六倍性能,来自单线程指令执行能力、核间带宽和芯片外部带宽。谈GPU时,人们经常讨论倍数级提升;但在真实CPU工作负载上实现倍数级提升,非常罕见。
我为团队感到自豪。我们还有非常出色的路线图。更令人兴奋的是,几乎所有合作伙伴都在支持Vera,他们和我们一样兴奋。
Vera打开了一个全新的市场。Agent是一种新的工作负载。过去,我们为人类打造CPU;现在,我们需要为Agent打造CPU。Agentic系统的属性不同,为什么还要沿用过去的CPU?我们将制造数以百万计的Vera。台湾ODM、计算机制造商和OEM会与我们共同进入市场。最早采用Vera的企业,正是Agentic计算公司。
这是一个过去从未存在的新市场。它不会取代传统市场,而是一个增量市场:面向Agent的CPU。这个市场一定会比过去更大,因为Agent的数量会远超人类,而且Agent非常没有耐心。谢谢大家。

6
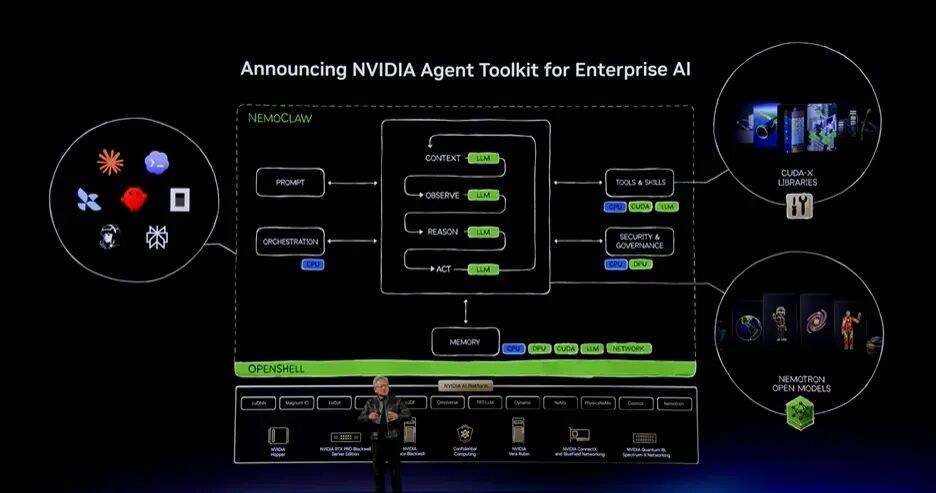
NVIDIA Agent Toolkit:企业Agent的操作系统
这是今天最重要的一张幻灯片。它展示的是未来十年的应用模式和计算模式:Agent Harness负责协调大语言模型。每一家公司都会运行这类系统,每一家公司、都会成为Agent公司,每一家公司内部都会运行Agent。
每一家公司都会意识到,Agent需要自己的操作系统。企业一直在问我们:如何安全运行Agent?如何为自身工作负载构建Agent?因此,我们推出NVIDIA Agent Toolkit for Enterprise AI。
其实,大家一直都在亲眼看着我们构建它。NVIDIA在GTC上宣布的许多技术,都经过多年铺垫。回看五年前或十年前的GTC,就会发现今天的成果早已开始酝酿。
企业要构建Agent即服务,或者部署Agent执行任务,需要四类要素。
第一,当然是模型,也就是大语言模型:越智能越好、越便宜越好、越快越好。
第二,需要Harness协调全部流程。
第三,模型需要使用工具,而工具会附带技能。前面展示的CUDA-X库,未来会成为Agent极为强大的工具。
第四,需要Runtime,也就是把所有部分连接起来的操作系统。
这就是NVIDIA面向Agent的Toolkit。它包含可以修改的世界级开放模型,也可以运行来自任何公司的Agent,例如ClaudeCode和Codex。
Agent可以运行在NVIDIA Open Shell安全Runtime中。Open Shell为Agent提供身份管理、隔离、策略、隐私和安全控制,使其能够在企业内部、云端和终端设备上更加安全地运行,在企业内部获得很高的安全性。
Open Shell会保护Agent,使其始终受到安全策略约束;隐私会受到保护,权限可以被控制,身份也会受到保护。Open Shell正在全球范围内获得采用,而且NVIDIA Open Shell是开源的。
未来会有许多企业采用Open Shell,包括RedHat、Canonical和Microsoft。Open Shell会广泛部署。它是一层关键Runtime,并且针对无处不在的NVIDIA AI平台进行了充分优化。无论是在云端、本地数据中心还是设备端,都可以运行Open Shell。
现在,你拥有Agent可使用的工具和库;拥有可以直接使用或修改的模型;也拥有Harness。不同Agentic Harness可以在本地或任何位置运行。模型、Harness、工具与技能、Runtime,这四层共同构成现代企业的Agent操作系统。
Cadence Chip Stack:芯片设计超级Agent
如何使用这套能力?我最喜欢的Agent使用场景之一,就是芯片设计。芯片设计是NVIDIA最重要的工作,因此我们当然要与Cadence合作,打造芯片设计Super Agent。
它可以由Codex或ClaudeCode负责协调,以RTL、架构图、原理图和规格说明作为输入,并处理需要修复的问题。我们与Cadence一起创建了针对NVIDIA Runtime优化的Super Agent,并使用Nemotron。让我们来看一下。
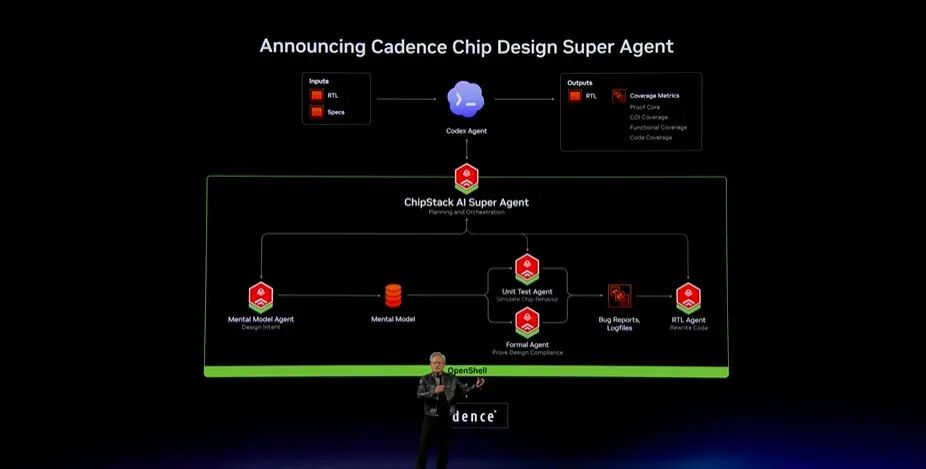
(以下为现场影片内容)Cadence和NVIDIA正在合作构建芯片设计Agent。数十万颗NVIDIA芯片共同构成AI工厂,为全球前沿AI模型提供动力。设计这些芯片以及运行芯片的系统,是工程领域最困难的问题之一:数万亿晶体管、三维电路、微观尺度,每一道逻辑门、每一条线路都必须在皮秒级保持同步,不能留下任何误差空间。
物理原型速度太慢、成本太高,因此工程师在数字世界中完成工作。每一颗芯片首先从一组架构规格开始,再被翻译成RTL,也就是芯片设计语言。RTL必须通过仿真验证。一个Bug就可能让芯片延期数月。
在NVIDIA,数千名工程师每年投入数十亿小时的计算资源,编写、运行并调试数以百万计的测试。一个循环往往需要团队花费数周时间。为了压缩这个周期,Cadence和NVIDIA构建了设计验证Agent。
Codex负责编排流程。Cadence Chip Stack启动RTL验证循环,由Nemotron驱动,并受到NVIDIA Open Shell保护。系统可以调用一批专家子Agent,分别负责RTL生成、Testbench创建、回归测试和调试。整套系统能够自行推进。
Chip Stack Agent使用Cadence X celium运行数百次仿真,并使用Jasper执行形式化验证。设计缺陷被暴露出来,代码中的Bug随后被修复。过去需要数周完成的工作,现在可以压缩到数小时,验证周期加速超过40倍。
Cadence与NVIDIA正在用AIAgent重新发明芯片设计,把周期从数周压缩到数小时。
Nemotron 3 Ultra:面向长时运行Agent的开放模型
NVIDIA有数千名芯片设计师,未来我们会“聘用”数十万个Cadence Super Agent与工程师共同工作,从而加速公司运转,让我们能够更加雄心勃勃,创造更多卓越产品,并以更快速度推进。
前面已经看到,Toolkit包括模型、Harness、工具和Runtime。在这个案例中,工具就是Cadence的仿真器、验证器和形式化验证系统。这也是NVIDIA努力用CUDA加速Cadence工具的原因:Agent没有耐心,希望立刻得到结果。模型、Harness、加速库、工具和Runtime,在这里共同发挥作用。
这套系统首先需要一个优秀模型,让Cadence能够根据自身工作流与专业知识进行修改和调优,打造包含专有知识的Super Agent。这个模型就是Nemotron。
NVIDIA致力于为全球构建开放模型,让每个人都能创建自己的Agent。今天,我们宣布Nemotron 3Ultra,也就是下一代开放模型。它非常智能。

Nemotron不只提供模型本身,也会提供训练模型所使用的数据。我们拥有由优秀合作伙伴组成的联盟,大家彼此协作并贡献数据。Nemotron使用全球规模最大的长时推理与长时工具调用任务数据集之一进行训练。模型、训练脚本和数据都会向大家开放。
这就是开放模型应有的方式。目标很简单:大家可以拿走全部内容,在此基础上继续增加自己的数据和能力,让模型变得更好,也让它真正属于自己。
Nemotron 3 Ultra的速度提高五倍。它是首批采用SSM(State Space Model)与MoE(Mixtureof Experts)混合架构的模型之一。这套架构速度极快。我们希望它能够更快地思考:思考速度越快,在相同成本下能够执行的推理步骤就越多。
它的整体运行成本还降低约30%,无论是总FLOPs还是总推理时间,都比全球最具成本效率的开放模型更低。我们对比的是全球最优秀的开放模型。
前沿级智能、五倍速度、低30%成本,并且完全开放。NVIDIA会长期投入。现在是Nemotron 3,我们也正在开发Nemotron 4。
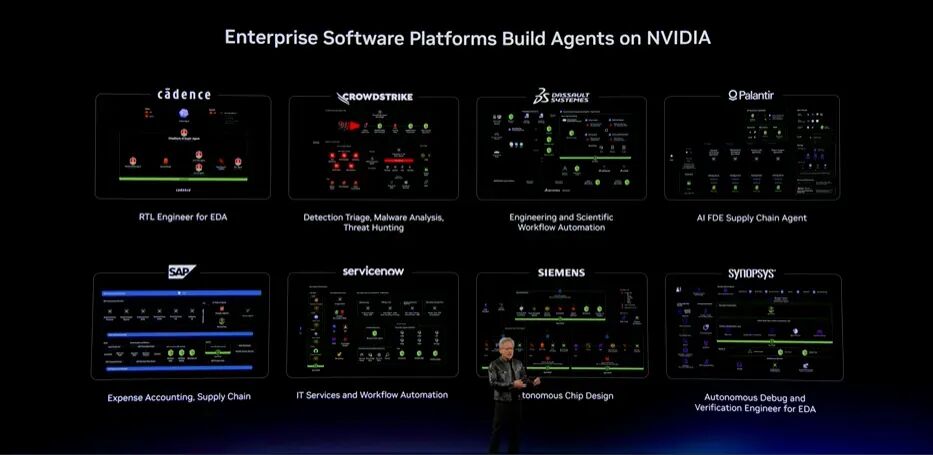
从模型、Harness、工具与技能到Runtime,这套Toolkit让全球每一家企业和企业软件公司都能够创建自己的Agent,就像Cadence构建Super Agent一样。我们还在与CrowdStrike、Palantir、SAP、ServiceNow等许多企业合作。
过去有人说:“Jensen,Agent会颠覆这些市场。”我的判断恰恰相反。现在大家已经能够看到,Agent会为合作伙伴创造前所未有的机会。NVIDIA Agent Toolkit for EnterpriseAI将帮助他们把握机会。
到这里,前三项重点已经清晰:第一,Vera Rubin已经进入全面量产爬坡阶段;第二,VeraCPU是为新一代Agent打造的CPU;第三,NVIDIA Enterprise Agent Toolkit让每一家企业和企业软件公司都能够构建Agent。
7
NVIDIA×Microsoft:重新发明Windows PC
我与大家的合作关系从这里开始,在座许多朋友和合作伙伴的公司也从这里起步。从很多角度看,这里是现代计算机产业的起点。
四十年前,PC产业已经开始形成。当时有Windows1、Windows2、AppleI和AppleII。
NVIDIA成立时,Windows3.1已经成为PC的代表。之后,Windows95让PC真正个人化:它把PC从企业设备变成消费电子产品,让每个人都应该拥有一台,而今天每个人也确实拥有一台。
PC平台在一开始就做对了几件非常重要的事情。Windows不只是解耦式系统,还进行了恰到好处的抽象。系统总线、开放芯片组、可以在运行时连接和安装的驱动程序,以及包含多媒体API的抽象层,共同打开了今天大家熟悉的PC世界。每一个要素都对PC普及不可或缺。
四十年后,Microsoft和NVIDIA将共同重新发明PC。这会成为新一代PC。
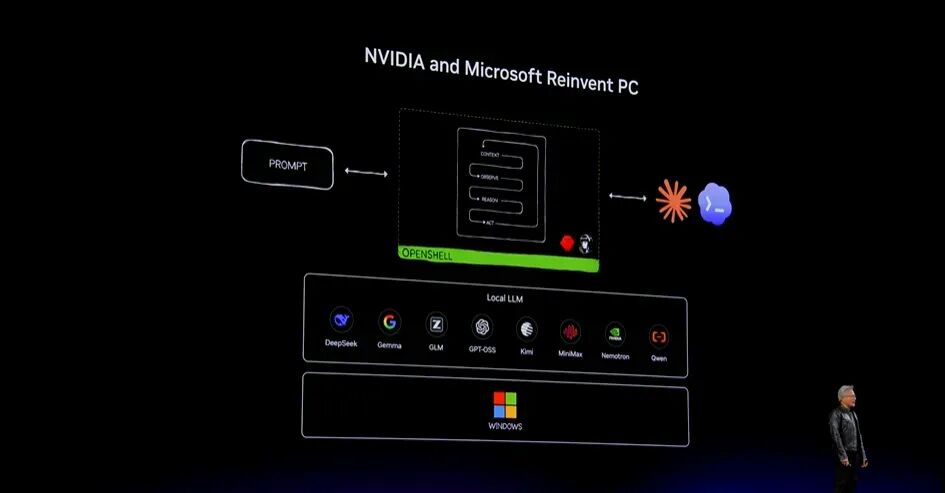
明天晚上——按照我们这里的时间——我会与Satya Nadella一起进一步介绍Microsoft与NVIDIA的合作。我们用了大约三年时间,才彻底重新构想PC的工作方式,为这一刻做好准备。
前面提到的Agent计算模式,会运行在AI云中,会运行在企业内部,也会运行在你的PC上。当一台PC拥有自主Agent,会发生什么?这个Agent会帮助你、理解你。你可以与它对话,它能够看见你;你可以让它阅读文件、帮助研究,还可以完成更多任务。
新的操作系统当然包含传统操作系统,但还会增加大语言模型。从很多角度看,这像是现代版的Direct X:它拥有输入和输出能力,能够理解Prompt,理解计算机视觉,生成视频和声音。这是PC的智能扩展。
在这之上,过去的应用程序会逐步被Agentic Runtime和Agent扩展或替代。Agent会成为现代应用。让我们看看它能够做什么。
RTX Spark:个人Agent时代的新型Windows PC
(此处为视频)一切始于一个火花:一个四十年来首次重新构想PC的想法。进入AI时代,当Agent原生运行在PC上,同时连接本地或云端模型,个人AI被隔离在安全沙箱中,持续运行并完成工作,个人计算机会变成什么?芯片和操作系统都必须演进。
现在介绍NVIDIA RTX Spark:把NVIDIA过去33年学到的一切,浓缩进一颗芯片。
它包含BlackwellRTXGPU、6144个CUDA Core、约1P FLOP AI性能,以及与Media Tek合作打造的20核Grace CPU。CPU与GPU通过NVLink-C2C连接;系统拥有128GB统一内存,采用台积电3纳米工艺,集成约700亿个晶体管。NVIDIA还与Microsoft紧密合作,为Agent构建Windows平台。
我们正在为创作、游戏和Agent重新发明个人电脑。这是新一轮个人计算革命的黎明,而一切从NVIDIA RTX Spark开始。(视频结束)
这就是它。当然,我必须展示最漂亮的部分,也就是视频游戏。这与NVIDIA的初心最接近。这里是《Forza》,这里是新的007游戏。我很期待玩到它。我看起来甚至有点像里面的角色。女士们、先生们,这就是NVIDIA RTX Spark笔记本电脑。

谢谢大家。我的口袋里有太多东西了。这是我们打造过的最惊人的芯片之一:N1X,由NVIDIA与Media Tek合作打造。我刚才好像看到了Rick。这就是N1X,非常漂亮。
坦率地说,这是一颗需要NVIDIA积累33年才能打造出来的芯片,因为NVIDIA100%的软件栈都能在这里运行。数字生物学、地震处理、天体物理学、CUDA相关能力、物理、生物、基因组学、AI、计算机图形学,都没有问题。NVIDIA创造过的所有应用,以及Windows运行过的所有应用,都可以在这台计算机上运行。

Microsoft与NVIDIA对所有部分进行了细致优化,让这台计算机几乎能够运行世界上已经创造出来的一切,同时还能运行Agent。这是一台非常惊人的计算机,我为它感到自豪。
本地Agent演示:从建筑概念到渲染图
请记住刚才那一点。在接下来的视频中,请想象所有工作都可以在你的PC上运行。计算机可以运行本地Nemotron 3 Ultra或其他Nemotron模型,也可以连接云端的Claude Code、Codex或其他模型,再完成非常惊人的工作。让我们来看一下。
(此处为视频)每一栋房子都始于一个想法。从想法走向设计,需要大量工具、专业能力和时间。现在,一个在RTX Spark本地运行的Agent,可以使用笔记本电脑里的工具帮助我设计房子。它运行在Open Shell沙箱中,使用Hermes Harness,并连接云端Claude Sonnet。
我选择一个地点,分享概念草图和风格Mood Board,再通过Prompt描述需求与设计意图。Agent随后开始使用笔记本电脑里的工具工作。
它打开Rhino,开始建立场地模型,处理地形、退界和建筑体量。随后,它提出针对成本、舒适度和品质优化过的建筑形态。在形态确定后,Agent生成室内布局:墙体、动线和房间逐步成形。我可以随时介入调整。门、窗和结构构件会自动放置。Agent还会发现并修复自身错误。
经过确认后,Agent把模型从Rhino导出至Blender,材质和物体属性也会随之迁移,完整保留设计上下文。我进一步微调材质,让效果达到预期,然后选择镜头。Blender对房屋进行渲染。Agent再使用Flux2模型进行生成式AI处理,把不同视角和光照条件下的渲染图转化为照片级图像。
过去非常复杂的工作流,现在可以由RTX Spark上的Agent引导并简化,让设计以想象力的速度推进。(视频结束)
在Agent时代,开发者对这台计算机非常兴奋。它拥有完整加速能力和软件能力,我们也正在与开发者合作,让它为所有用户发挥价值。
下一个例子是Adobe。Adobe拥有全球数千万用户使用的优秀工具套件。Adobe重新设计了Photoshop和Premiere的核心架构,并将为RTX Spark发布相应版本,速度达到原来的两倍。它们本来已经很快,现在还会再快一倍。同时,这些工具也针对Agent进行了设计:借助MCP Server,它们可以与笔记本电脑上的Agent交互。
希望把RTX Spark推向市场的客户与合作伙伴非常多。对于PC行业而言,这是四十年来首次出现的全新产品线。我非常高兴全球生态都加入进来。几乎所有主要厂商都会支持RTX Spark,与NVIDIA一起打造智能、强大、漂亮的笔记本电脑。

笔记本、桌面Agent电脑与DGX Station for Windows
但事情还不止于此。RTX Spark重新发明了笔记本电脑,而Microsoft与NVIDIA实际上要重新发明整个PC品类。
今天,我们宣布一整套全新产品线:覆盖桌面机、笔记本和工作站的三类革命性Windows设备。它们100%兼容Windows,100%支持CUDA,100%支持NVIDIA AI Tensor Core。大家看到NVIDIA在全球各类平台上运行的能力,都可以在这里运行。这是四十年来第一次完全重新设计、重新发明的PC产品线。
这里是RTX Spark笔记本电脑。这里是桌面机,这一台来自MSI。

Agent可以全天候免费运行。你可以下载自己的Agent,也可以在这里运行自己的OpenClaw。它始终在线,不会有按量计费焦虑。它可以连接整栋房子:笔记本电脑、显示屏、摄像头、烘干机、饮水机、热水器、安全系统,以及你希望连接的一切。这会成为你的个人AIAgent。
它还会越来越聪明。今天有Nemotron 3 Ultra,未来还会有Nemotron 4、Nemotron5和Nemotron6。模型会持续变得更智能,而这台设备就放在家里,不断帮助你处理事情。需要预订旅行?没有问题。
如果希望获得更强系统,这里还有NVIDIA DGX Station for Windows。它能够兼容Windows生态,拥有768GB内存,因此可以运行万亿参数模型。它提供约20PFLOPSAI性能和8TB/s内存带宽,可以直接放在桌边。对于大语言模型和Agent开发者而言,桌边拥有这样一套系统,就相当于拥有开发所需的算力;真正部署时,再把工作负载迁移到云端。

仔细思考会发现,一些重要变化正在发生。十五至二十年前,我们对“手机”的理解与今天不同。今天,人们拿手机做的事情很多,但最少做的反而可能是打电话。因此,“手机”的含义已经与过去完全不同。
我确信,十年后的PC与今天理解的PC也会大不相同。今天,PC还是一种打开应用、点击和输入的工具;未来,它会变成完全不同的东西。
我有一个设想。今天,许多家庭拥有家庭影院、大电视、割草机、洗碗机。未来,每个家庭也可能拥有一台AI超级计算机,持续运行所有Agent和助手,为你处理各种事务。就像家里需要家庭影院、音响和游戏主机一样,也会需要一台在家中运行的AI Agent Computer。
随着时间推移,它对你的意义会更接近R2-D2或C-3PO,而不是一台传统PC。毫无疑问,计算机的这次重塑,与手机演变成智能手机一样重要。这是一段新旅程的开始。
这也是一条全新产品线的开始。NVIDIA已经为它制定路线图。每一代架构都会对应桌面机、笔记本和工作站。令我非常高兴、也深感荣幸的是,全球几乎整个PC产业都加入进来,与NVIDIA一起重新发明PC:新的产品线,新的起点。谢谢大家。
8
Physical AI:从Agent扩展到机器人与现实世界
大家知道,AgenticAI本质上就是数字机器人。它能够理解、推理、规划、行动并使用工具。AgenticAI会运行在各种计算机上。过去一段时间,我已经陆续介绍过这些方向。
我们在开发人形机器人,也在开发各种机器人计算机;我们在开发自动驾驶汽车计算机,也在开发卫星计算机。GeForce GPU拥有TensorCore。刚才,我还介绍了一整套新的PC产品线。未来,农业设备、制造设备和重工业设备都会具备Agentic能力。每个人甚至都会拥有一个小型Agent助手。
基站也会如此。未来的无线电基站会具备Agentic能力:理解流量,并思考如何与其他基站协同,以尽可能少的能源提升利用率和频谱效率。因此,一切设备都会运行Agent。
今天,NVIDIA的业务仍然主要集中在中心侧,但我确信,未来全球会运行数百亿、甚至数千亿套Agentic系统和Agentic计算机。
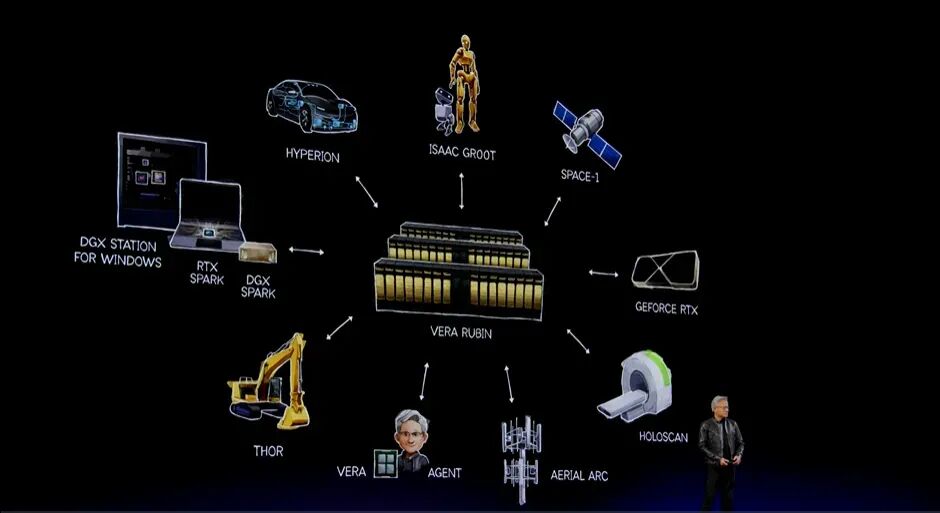
Cosmos3:Physical AI的开放全模态世界模型
其中最大的难题是数据。对于语言模型而言,我们在互联网上训练所使用的英语和其他语言文本,来自人类视角:由人类书写,也由人类阅读。
但要为AI机器人创建数据,数据必须来自机器人的感知视角。全球大部分视频数据是第三人称,而不是第一人称。因此,对于Agentic系统、机器人系统和Physical AI而言,数据是最困难的问题。
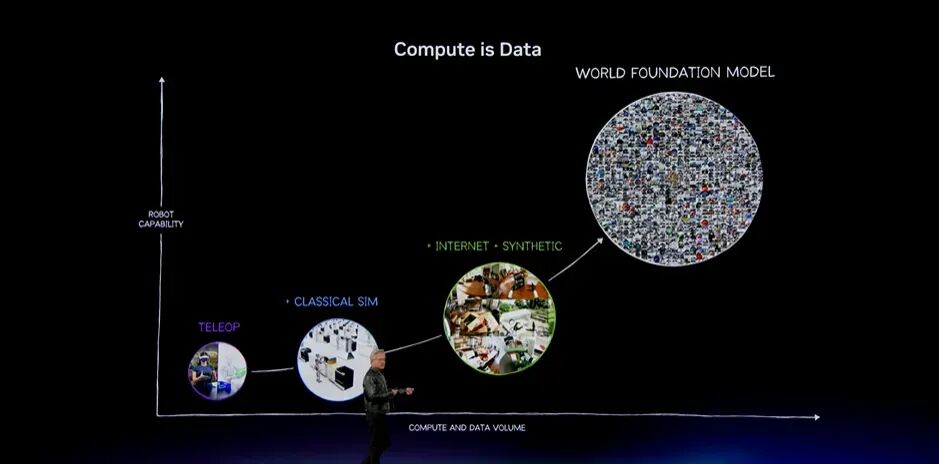
大家已经看到,我们沿着一条路径逐步向上推进。首先是Teleoperation,也就是人类演示。这与强化学习中的人类反馈类似。随后,我们使用仿真,这正是Omniverse发挥作用的位置,也可以类比强化学习中的可验证奖励。
我们使用这些系统为Physical AI模型提供冷启动。最终,系统能够从第三人称视频中学习,再把内容重新投影为第一人称视角。经过不断Boot strapping,我们得到能够从任意视角理解物理世界的World Foundation Model:第三人称、第一人称、由外向内、由内向外,都没有问题。这是一个重大突破。
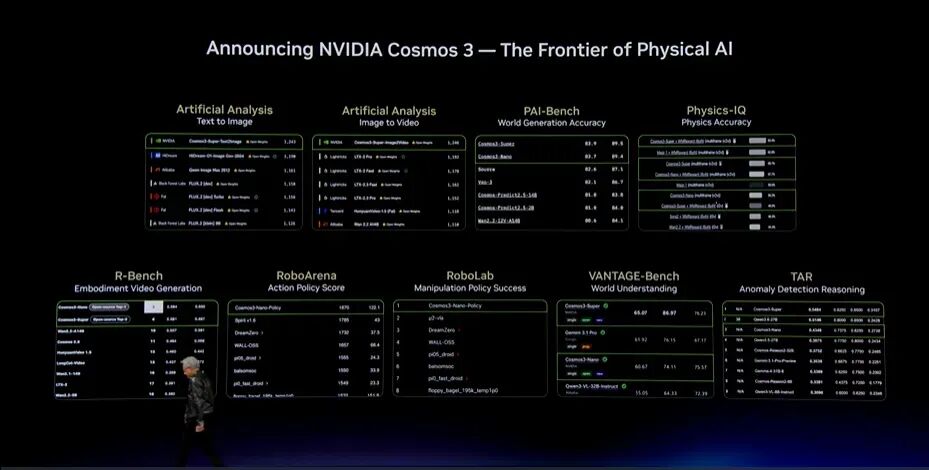
今天,我们宣布Cosmos 3,把Physical AI推向新的前沿。语言模型已经位于前沿,并且有许多人参与开发;在Physical AI领域,NVIDIA同样建立了非常强的能力。我为团队感到自豪。
Cosmos 3会成为Physical AI开发工作的基础模型。无论要构建何种机器人,包括工厂机器人和在工厂里工作的机器人,只要它需要理解物理世界,都可以使用Cosmos 3。它能够理解和推理,也能够生成内容,进入仿真闭环,甚至直接成为Policy。它在多个排行榜上处于领先位置。让我们来看一下。
推理型自动驾驶模型
(此处为视频)现实世界无限复杂且无法预测。Physical AI需要数据,但现实世界数据无法无限扩展。对于Physical AI而言,算力就是数据。
Cosmos是面向Physical AI的开放前沿全模态模型,采用新的Mixture-of-Transformers架构。像素、动作、声音和语言流入自回归Transformer,由它完成推理、规划,并向Diffusion Transformer发出指令;后者负责生成接下来会发生什么。
开发者可以针对不同机器人形态和使用场景,对Cosmos进行后训练。作为VLM,Cosmos观察物理世界,理解正在发生什么,描述场景并标记重要内容。作为WorldModel,Cosmos能够基于图像、文字或视频生成符合物理规律的合成视频。作为Simulator,Cosmos可以闭合Policy训练与评估循环。
Cosmos还是NVIDIA Omni Dreams的基础。Omni Dreams是一种以动作为条件的World Model,能够逐帧预测未来。对Cosmos进行后训练后,它还可以变成World Action Model:感知、推理、规划,并为各种机器人和一切移动设备生成动作。
这是一种新的数据,也是一种由计算机生成的新型教师。Cosmos会成为Physical AI时代开发者的基础。(视频结束)
过去,数据加算力得到AI。现在,我们已经拥有AI,因此算力本身也可以生成数据。使用Cosmos3,可以训练大量AI模型。
Cosmos与Nemotron类似,都是开放模型系统。我们开放模型、开放数据,也开放训练方法,让开发者可以进一步增强它,把Cosmos转化为自己的专有模型。我们正在与多个行业的优秀伙伴合作。

9
自动驾驶:DRIVE Hyperion与Al pamayo 2 Super
为机器人研究提供开放参考平台
模型当然是AI栈中最容易理解的部分,但完整AI栈要复杂得多。它还包含生成器、模型、模拟器和Runtime,就像Agentic系统一样。
自动驾驶汽车本质上是一种Physical AI和Agentic Robot,同样需要复杂技术栈。今天,我们宣布面向自动驾驶汽车的开放模型NVIDIA Alpamayo2 Super。

我们正在与全球汽车公司合作。已经加入NVIDIA DRIVE Hyperion、并且正在构建DRIVEHyperion汽车的品牌,对应大约80%的全球汽车产量。未来会出现大量DRIVE Hyperion系统,既能够运行Alpamayo,也能够运行其他公司的自动驾驶技术栈。
我们还连接了移动出行服务。大约97%的全球移动出行服务生态都在与NVIDIA连接。当Alpamayo部署在DRIVE Hyperion Runtime和NVIDIAHalos安全系统上时,就可以接入全球范围的出行服务。让我们来看一下。

(视频)用户:嘿,Mercedes,带我去最喜欢的三明治店。
车辆:正在规划路线。车道畅通,开始驶出。由于前方静止车辆阻挡当前车道,向左微调。前方路口受停车标志控制,减速停车。行人进入当前车道,停车礼让。左侧有车辆切入,注意让行。右侧有车辆阻挡,微调轨迹并保持距离。前方出现新的车辆与障碍物,持续判断、减速、停车并保持安全距离。目的地在右侧。(视频结束)
Alpamayo是推理型自动驾驶模型。如果让它一直把思考过程说出来,可能会让乘客发疯。但我们很高兴它始终在“自言自语”,因为这就是思考。Alpamayo是一套让汽车具备推理能力的自动驾驶模型。
10
人形机器人:Isaac GR00T Reference Humanoid Robot
我们创造的技术当然也适用于人形机器人,其中还需要许多新的突破。NVIDIAIsaacGR00T是人形机器人的完整技术栈,覆盖模型、数据生成、仿真、Runtime和操作系统。这就是Isaac GR00T平台。

大家可以看到,无论是云端Agentic系统、PC上的Agentic系统、自动驾驶汽车机器人系统,还是人形机器人系统,基础模式都完全相同。
在每一种场景中,NVIDIA都会完整构建技术栈:纵向整合,采用ExtremeCo-Design,再把各个部分开放出来,让开发者按需选择和修改。
但还缺少一项关键能力:机器人系统需要参考平台。机器人非常复杂,包含大量电机和传感器,而且十分精密。我们需要像交付PC、DGX、云平台和自动驾驶参考平台一样,为机器人提供参考平台。
今天,我们宣布NVIDIA Isaac GR00T Reference Humanoid Robot:一套完整集成的人形机器人参考设计。它采用31个自由度的UnitreeH2Plus人形机器人本体,并配备SharpaWave五指灵巧手,每只手拥有22个自由度,整机合计75个自由度。它身高约六英尺、重量约150磅,和我有点像——第一个数字比我矮一点,第二个数字比我重一点,其他的总体接近。

这套平台运行Jetson Thor,并集成完整软件栈、数据生成栈、仿真栈和Runtime。它面向所有开发者,但尤其适合高校和大学研究人员,因为从零构建这样一台机器人极其困难。让我们来看一下。
(视频)AI的下一次跃迁是通用机器人,也就是人形机器人。但构建一台人形机器人非常困难。每一个团队都要从头开始,把仿真器、Teleoperation系统、数据流水线和训练基础设施拼接起来。研究真正开始之前,往往需要数月准备。
NVIDIA Isaac GR00T是面向人形机器人的开放开发平台:包含开放模型、仿真与训练库、数据生成器,以及完整的机器人计算机。系统已经完成端到端流水线连接,数小时内即可启动。
首先,在IsaacLab中建立仿真环境。随后,通过Isaac Teleop在真实或仿真机器人上捕获演示。再使用Omniverse与Cosmos生成合成数据,把一次演示扩展成数千次演示。之后训练Policy,并在IsaacLab-Arena中进行评估。最后,通过运行在Jetson Thor上的IsaacROS部署到机器人。
每一项组件都模块化并开放:可以使用NVIDIA提供的组件,也可以替换为自己的组件。GR00T正在为各个学科、各个领域的机器人研究提供动力,从研究实验室一直走向工厂车间。
现在,我们再加入一个新成员:基于NVIDIA开放平台打造的Isaac GR00T Reference Humanoid Robot。它已经为前沿研究做好准备,任何实验室都可以使用。机器人时代从这里开始。(视频结束)
11
总结:Agentic计算模式将复制到所有计算机
机器人非常多。NVIDIA正在与全球几乎所有参与机器人和机器人系统研发的公司合作。
过去六个月,计算机产业已经发生彻底变化。Agent与最新前沿模型汇聚之后,AI终于可以真正完成有用的工作。相同计算模式会一遍遍复制:一个Agent,由模型、Harness、带技能的工具和Runtime构成。Runtime会根据部署位置而变化:云端、本地、PC或机器人;但底层计算模式完全一致。
用户可以根据偏好使用不同Harness,也可以选择不同模型,并针对专有用途继续改进。还可以创建各种Super Agent,把它们提供给其他用户使用,帮助别人完成工作。
针对这种Agentic平台和Agentic模式,NVIDIA提供Enterprise Agent Toolkit。这是企业采用AI的有效路径,也是NVIDIA的重要增长机会。
Vera Rubin已经进入全面量产爬坡阶段。Grace Blackwell主要为AI、尤其是推理而打造;Vera Rubin则专门为运行Agent而打造。它远远不只是一颗GPU,而是一整套解耦式、分布式Agent处理系统。
NVIDIA已经真正转型为基础设施公司:不仅是GPU公司,不仅是系统公司,而是帮助客户尽快实现最大收入和最大利润的AI基础设施公司。
在Agent世界里,我们开始为Agent而不是为人类构建CPU。面向Agent的CPU有自己的特殊要求,而NVIDIA Vera是革命性产品。我非常高兴看到Vera进入量产爬坡。当前订单情况意味着,它有机会成为NVIDIA历史上最快、最成功的产品发布之一。
NVIDIA与Microsoft还共同创造了一整套新的PC产品线。这是一个新的起点。
相同的Agentic处理模式也会运行在各种设备中。刚才提到PC,但未来还会有机器人、卫星、基站、工厂、云端、本地数据中心和边缘设备。AgenticAI系统与Agentic计算模式会复制到全球各类计算机中。我们对个人电脑的理解也很可能随之改变。
感谢大家一直以来的合作与友谊。没有大家的共同努力,我们不可能走到今天。我为大家过去一年的成功感到自豪,而下一年还会更进一步。


书享界保留所有权 |书享界 » 智能体、AI PC、超算系统:黄仁勋GTC台北2026演讲完整实录